RDA DMP Common Standard for machine-actionable Data Management Plans
About this documentThis is a metadata application profile to provide basic interoperability between systems producing or consuming machine-actionable data management plans (maDMPS). Further fields can be added in specific deployments, but they do not guarantee interoperability. DMP tools can use any other fields in their internal data models. This application profile is intended to cover a wide range of use cases and does not set any business (e.g. funder specific) requirements. It represents information over the whole DMP lifecycle. For more information see examples, FAQ and useful links to consultations, documents, tools, prototypes, etc. developed by the working group.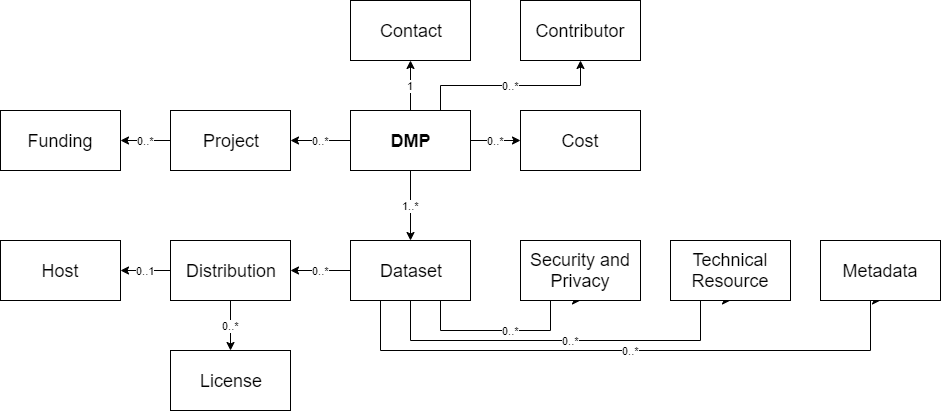
DMPProvides high level information about the DMP, e.g. its title, modification date, etc. It is the root of this application profile. The majority of its fields are mandatory.ProjectDescribes the project associated with the DMP, if applicable. It can be used to describe any type of project: that is, not only funded projects, but also internal projects, PhD theses, etc.FundingFor specifying details on funded projects, e.g. NSF of EC funded projects.ContactSpecifies the party which can provide any information on the DMP. This is not necessarily the DMP creator, and can be a person or an organisation.ContributorFor listing all parties involved in the process of the data management described by this DMP, and those parties involved in the creation and management of the DMP itself.CostProvides a list of costs related to data management.DatasetThis follows the defintion of Dataset in the W3C DCAT specification. Dataset can be understood as a logical entity depicting data, e.g. raw data. It provides high level information about the data. The granularity of dataset depends on a specific setting. In edge cases it can be a file, but also a collection of files in different formats. See <a href=https://github.com/RDA-DMP-Common/RDA-DMP-Common-Standard/blob/master/docs/FAQ.md>FAQ</a> for more details.DistributionThe term "distribution" used here is as defined by the very widely used W3C DCAT metadata application profile. It is used to mean a particular instance of a dataset that has been, or is intended to be, made available in some fashion. It is important to separates the logical notion of a "dataset" from its distributions, of which there may be several, especially to attach more specific metadata properties such as "size" and "license". The lifecycle of the DMP has no particular bearing on this, and a "distribution" may be defined even if the DMP is never actually realised.LicenseUsed to indicate the license under which data (each specific Distribution) will be made available. It also allows for modelling embargoes. See <a href=https://github.com/RDA-DMP-Common/RDA-DMP-Common-Standard/blob/master/docs/FAQ.md>FAQ</a> for more details.HostProvides information on the system where data is stored. It can be used to provide details on a repository where data is deposited, e.g. a Core Trust Seal certified repository located in Europe that uses DOIs. It can also provide details on systems where data is stored and processed during research, e.g. a high performance computer that uses fast storage with two daily backups.Security and PrivacyUsed to indicate any specific requirements related to security and privacy of a specific dataset, e.g. to indicate that data is not anonymized.Technical ResourceFor specifying equipment needed/used to create or process the data, e.g. a microscope, etc.MetadataProvides a pointer to a metadata standard used to describe the data. It does not contain any actual metadata relating to the dataset.AffiliationFor specifying the organisation(s) to which a contact or contributor belongs.Alternate IdentifierFor specifying alternate identifiers for a DMP or a dataset, e.g. an internal identifier used by a DMP tool. This is in alignment with the DataCite Metadata Schema.Related IdentifierFor specifying related identifiers for a DMP or a dataset, e.g. a DOI of a publication that describes the data management described in this DMP. This is in alignment with the DataCite Metadata Schema. | Structure
|
Properties in 'affiliation'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| affiliation_id | Identifier for an affiliation | Nested Data Structure | 1 | |
| name | Name of an affiliation | String | 1 | Some University |
Properties in 'affiliation_id'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| identifier | To indicate the specific value of an identifier for an affiliation | String | 1 | 03yrm5c26 |
| type | To specify a type of an identifier for an affiliation. Suggested Values: ror, grid, isni | String | 1 | ror |
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| identifier | Value of the identifier | String | 1 | E-GEOD-34814 |
| type | Type of the identifier | String | 1 | Local accession number |
Properties in 'contact'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| affiliation | Affiliations of a contact | Nested Data Structure | 0..n | |
| contact_id | Identifier for a contact | Nested Data Structure | 1..n | |
| mbox | E-mail address for a contact | String | 1 | cc@example.com |
| name | Name of a contact person or organisation | String | 1 | Charlie Chaplin |
Properties in 'contact_id'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| identifier | To indicate the specific value of an identifier for a contact | String | 1 | 0000-0000-0000-0000 |
| type | To specify a type of an identifier for a contact. Suggested Values: orcid, isni, openid | String | 1 | orcid |
Properties in 'contributor'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| affiliation | Affiliations of a contributor | Nested Data Structure | 0..n | |
| contributor_id | Identifier for a contributor | Nested Data Structure | 0..n | |
| mbox | E-mail address for a contributor | String | 0..1 | john@smith.com |
| name | Name of a contributor | String | 1 | John Smith |
| role | Contributors role(s) within the process of data management (incl. planning). It is recommended to use contributor types of DataCite Metadata Schema. | String | 1..n | DataManager, Researcher |
Properties in 'contributor_id'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| identifier | To indicate the specific value of an identifier for a contributor | String | 1 | 0000-0000-0000-0000 |
| type | To specify a type of an identifier for a contributor. Suggested Values: orcid, isni, openid. | String | 1 | orcid |
Properties in 'cost'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| currency_code | Allowed values defined by ISO 4217. | Term from Controlled Vocabulary | 0..1 | EUR |
| description | To provide additional details about a cost, including specifying which activities or resources it relates to, such as making data FAIR, ensuring data accessibility, or enhancing its reusability. | String | 0..1 | Storage and backup costs are calculated based on a 12-month storage period, daily incremental and weekly full backups, and a frequency of 4 restores per month, as outlined in the evaluation table at www.example-storagecostevaluation.com. |
| title | Title of a cost | String | 1 | Storage and backup |
| value | Cost value in the specified currency | Number | 0..1 | 1000 |
Properties in 'creator'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| affiliation | Affiliations of a creator | Nested Data Structure | 0..n | |
| creator_id | Identifier for a creator | Nested Data Structure | 0..n | |
| mbox | E-mail address for a creator | String | 0..1 | john.doe@example.com |
| name | Name of a creator person or organisation | String | 1 | John Doe |
Properties in 'creator_id'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| identifier | To indicate the specific value of an identifier for a creator | String | 1 | s0000-0000-0000-0000 |
| type | To specify a type of an identifier for a creator. Suggested Values: orcid, isni, openid, other |
String | 1 | orcid |
Properties in 'dataset'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| alternate_identifier | To provide alternative identifiers for a dataset, which can be used to reference or cite the dataset in different contexts or systems. Alternative identifiers can include local accession numbers, internal database IDs, or other unique codes assigned to the dataset by various organizations or repositories. | Nested Data Structure | 0..n | |
| creator | To specify the creators of the dataset. | Nested Data Structure | 0..n | |
| data_quality_assurance | To describe any quality assurance processes applied to a dataset, such as, to ensure its accuracy, reliability, consistency, and usability for its intended purposes. This includes systematic practices, procedures, and policies designed to maintain high data quality throughout its lifecycle. | String | 0..n | We calibrate measuring equipment daily, run repeat samples to monitor consistency in measurements and results, and cross-check collected data with at least two colleagues for accuracy. |
| dataset_id | Identifier for a dataset | Nested Data Structure | 1 | |
| description | Description is a property in both Dataset and Distribution, in compliance with W3C DCAT. In some cases these might be identical, but in most cases the Dataset represents a more abstract concept, while the distribution can point to a specific file. | String | 0..1 | The dataset includes detailed measurements of temperature, humidity, and soil moisture levels collected at various time intervals (every 30 minutes) across multiple locations. The dataset will also include metadata such as GPS coordinates, sensor calibration data, and environmental conditions. The primary objective of this dataset is to analyze the correlation between these variables and their impact on plant growth patterns over a 6-month period. |
| distribution | To provide technical information on a specific instance of data. | Nested Data Structure | 0..n | |
| is_reused | Indication if the dataset is reused, i.e., not produced in project(s) covered by this DMP. | Boolean | 0..1 | true |
| issued | To indicate a date when a dataset was published or released. Encoded using the relevant ISO 8601 Date compliant string | Date | 0..1 | 2019-06-30 |
| keyword | Keyword | String | 0..n | keyword 1, keyword 2 |
| language | Language of the dataset expressed using ISO 639-3 | Term from Controlled Vocabulary | 0..1 | eng |
| metadata | To describe metadata standards used. | Nested Data Structure | 0..n | |
| personal_data | To indicate whether a dataset contains personal data. Personal data refers to any data that can identify an individual (e.g. name, birthdate, address, voice recordings, etc.). Allowed Values: yes, no, unknown |
Term from Controlled Vocabulary | 1 | unknown |
| preservation_statement | To outline a plan for how and why a dataset will be preserved for long-term access, including for example storage redundancy, integrity checks (checksums, fixity checks), format migration, and a sustainability plan ensuring institutional commitment and funding. | String | 0..1 | All research data will be stored in the university's secure data repository, backed up daily to ensure redundancy and prevent data loss. The dataset will be preserved in a standardized format (e.g. CSV, JSON) and will include detailed metadata for clarity. It will be accessible to the public via the university’s open-access platform three months after the completion of the project, with ongoing access ensured for a minimum of 5 years. Regular checks will be performed every 6 months to confirm the integrity and readability of the data. |
| rights | A statement that concerns all rights not addressed with license, such as copyright statements. | String | 0..1 | This dataset incorporates third-party materials that are subject to additional rights and restrictions. Users must obtain permission from the original rights holders before reuse. |
| related_identifier | To provide references to related resources, such as publications, datasets or software, that are associated with the dataset. This helps to establish connections between different research outputs and enhances the discoverability and context of the dataset. | Nested Data Structure | 0..n | |
| security_and_privacy | To list all security and privacy measures applied to a dataset to protect sensitive information, for example encryption, anonymization, data masking, and compliance with data protection regulations (e.g. GDPR or HIPAA). It can also be used to express any security measures required for handling the dataset, e.g. only physical access, etc. | Nested Data Structure | 0..n | |
| sensitive_data | To indicate whether a dataset contains sensitive data. Sensitive data refers to information that could pose risks to individuals or organizations for example financial information, medical records, passwords and social security numbers. Allowed Values: yes, no, unknown |
Term from Controlled Vocabulary | 1 | unknown |
| technical_resource | List all technical resources (e.g. tools or software) required for any stage of a dataset lifecycle (e.g. microscopes, sensors, Jupyter Notebook, Galaxy workflows, measuring devices) | Nested Data Structure | 0..n | |
| title | Title is a property in both Dataset and Distribution, in compliance with W3C DCAT. In some cases these might be identical, but in most cases the Dataset represents a more abstract concept, while the distribution can point to a specific file. | String | 1 | Fast car images |
| type | If appropriate, type according to: DataCite and/or COAR dictionary. Otherwise use the common name for the type, e.g. raw data, software, survey, etc. https://schema.datacite.org/meta/kernel-4.1/doc/DataCite-MetadataKernel_v4.1.pdf http://vocabularies.coar-repositories.org/pubby/resource_type.html | String | 0..1 | image |
Properties in 'dataset_id'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| identifier | To indicate the specific value of an identifier for a dataset | String | 1 | 11353/10.923628 |
| type | To specify a type of an identifier for a dataset. Suggested Values: handle, doi, ark, url | String | 1 | handle |
Properties in 'distribution'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| access_url | A URL of the resource that gives access to a distribution of the dataset. e.g. landing page. | URL | 0..1 | http://some.repo... |
| available_until | Indicates how long this distribution will be/ should be available. Encoded using the relevant ISO 8601 Date compliant string | Date | 0..1 | 2030-06-30 |
| byte_size | Size of a distribution in bytes | Number | 0..1 | 690000 |
| data_access | Indicates access mode for data. Allowed Values: open, shared, closed |
Term from Controlled Vocabulary | 1 | open |
| description | Description is a property in both Dataset and Distribution, in compliance with W3C DCAT. In some cases these might be identical, but in most cases the Dataset represents a more abstract concept, while the distribution can point to a specific file. | String | 0..1 | This dataset contains measurements from a single research location at the University of California's Arboretum in Davis, California, collected every 30 minutes over a 6-month period from January 2024 until June 2024. Each file includes time-stamped data for temperature, humidity, and soil moisture, listed by date and time. The data is organized in CSV format, with each row representing a specific time point, including the location (UC Arboretum), timestamp, and the corresponding environmental variables. |
| download_url | The URL of the downloadable file in a given format. E.g. CSV file or RDF file. | URL | 0..1 | http://some.repo.../download/... |
| format | Format according to: https://www.iana.org/assignments/media-types/media-types.xhtml if appropriate, otherwise use the common name for this format | String | 0..n | image/tiff |
| host | To provide information on a system where data is stored. This can be all types of systems used within the whole data management lifecycle, i.e. temporary storage on networked hard drives, as well as, repository systems where data is shared with others. | Nested Data Structure | 0..1 | |
| issued | To indicate a date when a distribution was published or released. Encoded using the relevant ISO 8601 Date compliant string | Date | 0..1 | 2019-06-30 |
| license | To list all licenses applied to a specific distribution of data. | Nested Data Structure | 0..n | |
| title | Title is a property in both Dataset and Distribution, in compliance with W3C DCAT. In some cases these might be identical, but in most cases the Dataset represents a more abstract concept, while the distribution can point to a specific file. | String | 1 | Full resolution images |
Properties in 'dmp'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| alternate_identifier | To provide alternative or secondary identifiers for a DMP, which can be used to reference or cite the dataset in different contexts or systems. Alternative identifiers can include other PIDs from DMP storage systems, internal database IDs, or other unique codes assigned to the DMP by various organizations or services. | Nested Data Structure | 0..n | |
| contact | Contact person for a DMP | Nested Data Structure | 1 | |
| contributor | To list people that play role in data management related to this DMP, e.g. resoponsible for performing actions described in this DMP. | Nested Data Structure | 0..n | |
| cost | To list costs related to data management. Providing multiple instances of a 'Cost' allows to break down costs into details. Providing one 'Cost' instance allows to provide one aggregated sum. | Nested Data Structure | 0..n | |
| created | Date and time of the first version of a DMP. Must not be changed in subsequent DMPs. Encoded using the relevant ISO 8601 Date and Time (with timezone) compliant string | DateTime | 1 | 2019-03-13T13:13:00Z |
| dataset | To describe data on a non-technical level. | Nested Data Structure | 1..n | |
| description | Any text related to this DMP, optionally describing the project. It can include important information that doesn't fit elsewhere. | String | 0..1 | This DMP is for our new project |
| dmp_id | Identifier for the DMP itself | Nested Data Structure | 1 | |
| ethical_issues_description | To describe considerations that require compliance with laws and regulations (e.g. GDPR, animal welfare) due to the involvement of humans, animals, or sensitive information. This includes ensuring informed consent from participants, protecting privacy and confidentiality, and adhering to applicable legal and ethical standards throughout the research. | String | 0..1 | There are ethical issues, because... |
| ethical_issues_exist | To indicate whether there are ethical issues related to data that this DMP describes. Allowed Values: yes, no, unknown |
Term from Controlled Vocabulary | 1 | yes |
| ethical_issues_report | To indicate where a report/document that details all identified ethical issues (might be for example emit from a meeting with an ethical committee), preferably in URL format | String | 0..1 | http://report.location |
| language | Language of the DMP expressed using ISO 639-3 | Term from Controlled Vocabulary | 1 | eng |
| modified | Must be set each time DMP is modified. Indicates a DMP version. Encoded using the relevant ISO 8601 Date and Time (with timezone) compliant string | DateTime | 1 | 2020-03-14T10:53:49Z |
| project | To list all project(s) for which the data and work are described in this DMP | Nested Data Structure | 0..n | |
| related_identifier | To provide identifiers of related resources, e.g. a project page, previous DMP versions, or a publication that describes this DMP. | Nested Data Structure | 0..n | |
| title | Title of a DMP | String | 1 | DMP for our new project |
Properties in 'dmp_id'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| identifier | To indicate the specific value of an identifier for a DMP | String | 1 | 10.1371/journal.pcbi.1006750 |
| type | To specify a type of an identifier for a DMP. Suggested Values: handle, doi, ark, url | String | 1 | doi |
Properties in 'funder_id'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| identifier | To indicate the specific value of an identifier for a funder. It is recommended to use CrossRef Funder Registry. | String | 1 | 501100002428 |
| type | To specify a type of identifier for a funder. Suggested Values: fundref, url | String | 1 | fundref |
Properties in 'funding'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| funder_id | Identifier of a funder | Nested Data Structure | 1 | |
| funding_status | To express different phases of project lifecycle. Allowed Values: planned, applied, granted, rejected |
Term from Controlled Vocabulary | 0..1 | granted |
| grant_id | Identifier of a grant | Nested Data Structure | 0..1 | 1234567 |
Properties in 'grant_id'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| identifier | To indicate the specific value of an identifier for a grant | String | 1 | http://example.com/grants/776242 |
| type | To specify a type of an identifier for a grant. Suggested Values: doi, url | String | 1 | url |
Properties in 'host'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| availability | Availability of a host (preferably as a percentage) | String | 0..1 | 99,5 |
| backup_frequency | Frequency of backups provided by a host | String | 0..1 | weekly |
| backup_type | Location and/or type of the backup provided by a host | String | 0..1 | tapes |
| certified_with | To indicate host trustworthiness via a standard repository certificate. Allowed Values: din31644, dini-zertifikat, dsa, iso16363, iso16919, trac, wds, coretrustseal |
Term from Controlled Vocabulary | 0..1 | coretrustseal |
| description | Description | String | 0..1 | Repository hosted by... |
| geo_location | Physical location of a server (where the distribution is actually stored) expressed using ISO 3166-1 country code. | Term from Controlled Vocabulary | 0..1 | AT |
| host_id | Identifier of Host | Nested Data Structure | 0..n | |
| pid_system | PID System used by a host. Allowed Values: ark, arxiv, bibcode, doi, ean13, eissn, handle, igsn, isbn, issn, istc, lissn, lsid, pmid, purl, upc, url, urn, other |
Term from Controlled Vocabulary | 0..n | doi |
| storage_type | To indicate whether a host supports versioning of data distributions. | String | 0..1 | LTO-8 tape |
| support_versioning | Allowed Values: yes, no, unknown |
Term from Controlled Vocabulary | 0..1 | yes |
| title | Title | String | 1 | Super Repository |
| url | A URL of an infrastructure hosting a distribution of a dataset | URL | 1 | https://zenodo.org |
Properties in 'host_id'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| identifier | To indicate the specific value of an identifier for a host | String | 1 | https://example.org/repo |
| type | To specify a type of an identifier for a host. Suggested Values: url | String | 1 | url |
Properties in 'license'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| license_ref | Link to license document. | URL | 1 | https://creativecommons.org/licenses/by/4.0/ |
| start_date | If date is set in the future, it indicates embargo period. Encoded using the relevant ISO 8601 Date compliant string | Date | 1 | 2019-06-30 |
Properties in 'metadata'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| description | To provide any details on the choice of the metadata standard | String | 0..1 | The ISO 19115 Metadata Standard is applied to describe each geospatial dataset. Metadata includes the satellite's sensor type (e.g. Landsat 8 OLI), acquisition date, spatial resolution (30m), and cloud cover percentage. |
| language | Language of a metadata expressed using ISO 639-3 | Term from Controlled Vocabulary | 1 | eng |
| metadata_standard_id | Identifier of Metadata Standard | Nested Data Structure | 1..n |
Properties in 'metadata_standard_id'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| identifier | To indicate the specific value of an identifier for a metadata standard | String | 1 | http://www.dublincore.org/specifications/dublin-core/dcmi-terms/ |
| type | To specify a type of an identifier for a metadata standard. Suggested Values: doi, url | String | 1 | url |
Properties in 'project'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| description | Project abstract providing an overview of the project's goals and scope | String | 0..1 | This project aims to analyze the impact of urbanization on local biodiversity by collecting and assessing environmental data from multiple urban centers. Using remote sensing, field observations, and statistical modeling, the study will identify key factors influencing species diversity and habitat loss. The findings will support sustainable urban planning initiatives and inform conservation strategies. |
| end | Project end date. Encoded using the relevant ISO 8601 Date compliant string | Date | 0..1 | 2020-03-31 |
| funding | Funding related with a project | Nested Data Structure | 0..n | |
| project_id | Identifier of Project | Nested Data Structure | 0..n | |
| start | Project start date. Encoded using the relevant ISO 8601 Date compliant string | Date | 0..1 | 2019-04-01 |
| title | Project title | String | 1 | Our New Project |
Properties in 'project_id'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| identifier | To indicate the specific value of an identifier for a project | String | 1 | https://example.org/project |
| type | To specify a type of an identifier for a project. Suggested Values: doi, raid, url | String | 1 | url |
Properties in 'related_identifier'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| identifier | Value of the identifier | String | 1 | https://example.com/ |
| metadata_scheme | Name of the related metadata schema (if applicable) | String | 0..1 | DDI-L |
| relation_type | Type of relation between the resource and the related resource, suggested values from DataCite relationType | String | 1 | HasMetadata |
| resource_type | Type of the related resource, suggested values from DataCite resourceTypeGeneral | String | 0..1 | Model |
| scheme_type | Type of the related metadata scheme linked with scheme URI (if applicable) | String | 0..1 | XSD |
| scheme_uri | Link to the scheme of the identifier (if applicable) | URI | 0..1 | http://www.ddialliance.org/Specification/DDI-Lifecycle/3.1/XMLSchema/instance.xsd |
| type | Type of the identifier, suggested values from DataCite relatedIdentifierType | String | 1 | url |
Properties in 'security_and_privacy'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| description | Describe a security and privacy measure applied to a dataset to protect sensitive information | String | 0..1 | The dataset undergoes anonymization by applying data masking techniques. Names, addresses, and phone numbers are replaced with pseudonyms or randomly generated identifiers. Specific details, such as exact birthdates, are generalized into age ranges. |
| title | Title a measure applied to a dataset | String | 1 | Anonymization of Personally Identifiable Data |
Properties in 'technical_resource'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| description | Describe a technical resource (e.g. tools or software) required for any stage of a dataset lifecycle (e.g. microscopes, sensors, Jupyter Notebook, Galaxy workflows, measuring devices) | String | 0..1 | The Celestron 44102 Inverted Biological Microscope was used to examine biological samples, such as cells and microorganisms, with high-resolution optics. |
| name | Name a resource applied to a dataset | String | 1 | Celestron Microscope |
| technical_resource_id | Identifier of a technical resource | Nested Data Structure | 0..n |
Properties in 'technical_resource_id'
| Name | Description | Data Type | Cardinality | Example Value |
|---|---|---|---|---|
| identifier | To indicate the specific value of an identifier for a technical resource | String | 1 | https://example.org/resource |
| type | To specify a type of an identifier for a technical resource. Suggested Values: doi, url, other | String | 1 | url |